
NLP Interview Questions
0 5647
Intelligence is not just limited to us humans now, even machines are getting intelligent than us! Taking the epitome of machines like siri, echo, flying drones, Sophia the robot, etc.
It is quite evident that machines are enriching the height of logical thinking and problem solving through their learning abilities. But do you know what the ultimate base of these intelligent machines is? Natural Language Processing (NLP)!
Yes, NLP is used by the machines to learn and adapt to intelligence. Interesting, isn't it!

So, if you are looking for a career in such an interesting domain, then this blog is the right platform for you. In this blog, I will enlist frequently asked NLP Interview Questions and will also walk you through the answer to each question.
So, without further ado, let us start with our very first question, that is:
1) What is NLP?
NLP, the acronym for Natural Language Processing, is a method which is used to analyze and process the natural languages in order to make it understandable by the machines.
Machines then utilize the generated language to extract the required information for their functioning through the application of machine learning algorithms.
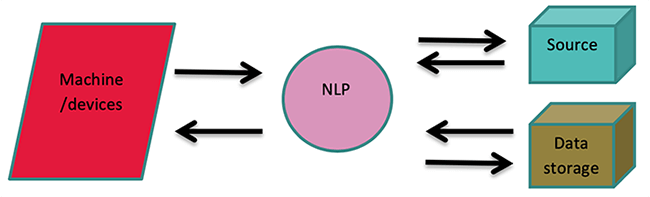
2) What are the defining components of NLP?
The major defining components of NLP are:
- Syntactic Analysis: It refers to the process of ordering the words in the sentence
- Pragmatic Analysis: This refers to the extraction of information from the words of the sentence
- Entity Extraction: This refers to the extraction of entities from the sentence such as events, name of the organization, etc.
3) Mention some of the applications of NLP.
Some of the applications of Natural Language Processing are:
- Name Entity Recognition
- Text Summarization and Classification
- Language Model Building
- Speech Recognition
- Spell Checking
- Machine Translation
- Character Recognition
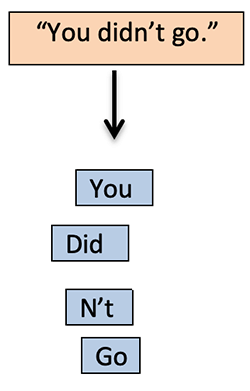
4) What is tokenization in NLP?
Tokenization is the process through which a sentence is split into smaller words known as tokens, containing the same character sequence.
For Instance:
5) What is Latent Semantic Analysis?
Latent Semantic Analysis is the process through which the relationship between any sets of documents and the containing terms are determined through the generation of concept related to that terms or documents.
6) Define the concept of POS (Parts of Speech) tagging in NLP.
Parts of Speech (POS) Tagging is the process through which the software, tagger, is used to label the words in a sentence with the help of an algorithm which then, assigns a parts of speech to every term or token analyzed in the given sentence.
These parts of speech include noun, pronoun, adjectives, etc.
7) How is Named Entity Recognition (NER) used in NLP?
In NLP, Named Entity Recognition is a process through which the named entities such as people, place, events, etc. are derived from a sentence and are further classified into predefined categories.
8) What is TF-IDF and what significance does it possesses in NLP?
TF-IDF stands for Term Frequency- Inverse Document Frequency. In Natural Language Processing, TD-IDF is used as a numerical analysis which determines how important a term is in context to any document or the collections.
9) What are NLP tools and libraries? Name them.
NLP tools and libraries are used to maintain and validate the overall processing of the language. Some of the important NLP tools and libraries are listed as below:
- Stanford Group's CoreNLP
- NLTK, the NLP library for python
- TextBlob, the interface for NLTK
- SpaCy, the performance tool for NLP
- Gensim, document similarity analysis tool
10) What are stop words in NLP? And how can we filter them?
Stop words in NLP refers to the words such as a, an; which does not imposes any value to the context of the sentence and omission of which, will not cause any change to the original meaning of the sentence.
The stop words in NLP can be filtered out with the help of NLTK library standard functions.
11) Clarify the NLP Terminology.
The varied factors which altogether formulate NLP terminologies are:
- Text Structures: Named entities, parts of speech tagging, Head of sentence
- Weight and Vectors: Length, TF-IDF, Word and Google Word Vectors
- Text Classification: Train set, test set, Supervised learning, LDA, text features, Dev (=validation) set
- Machine Reading: dbpedia, Entities extraction and linking, FRED (lib)
- Sentiment Analysis: Sentiment features, Sentiment entities, Sentiment dictionaries
12) What is Word Embedding in NLP?
Word Embedding is the process of Natural Language Processing which is based on language modeling and feature learning.
Through the word embossing technique, the mapping of the vectors for words in the given document is done in context to the real numbers.
13) What are NLG and NLU?
NLG refers to the Natural Language Generation where a new language is developed by processing the data from an old language.
On the other hand, NLU refers to the Natural Language Understanding through which the natural language is understood in order to understand the communication.
14) What is dependency parsing in NLP?
Dependency parsing in NLP is a process through which a sentence is assigned syntactic structure by analyzing the terms included.
If the terms are forming an ambiguity, a parse tree is generated until the ambiguity is eliminated.
15) What is the difference between regular expression and regular grammar?
A regular expression is the representation of natural language in the form of mathematical expressions containing a character sequence.
On the other hand, regular grammar is the generator of natural language, defining a set of defined rules and syntax which the strings in the natural language must follow.
Important Message: If you want to learn about Artificial Intelligence, you can also visit our
latest blog on Top 15 Artificial Intelligence Questions.

Share:
You May Also Like




Discount Coupons


Expand Your Business Reach


Comments
Waiting for your comments